Instagram Image Exploration and AI Analysis
Introduction
This project had two goals. First, I explored methods for including images in Tableau. It’s useful for visualizations about image data to include the relevant visual reference. Second, I delved into the research question, how do the results of AI image analysis correspond or differ from my own assignation of labels to my own Instagram photos? Audiences for this analysis are myself, as I like my photos and enjoy working with them, along with those who are interested in the inclusion of imagery in Tableau or the current state of AI assisted image analysis.
Data Source
To explore this question I downloaded my personal photos and data from Instagram using their recently implemented Data Download tool. Instagram only recently began making users’ personal data available to them. It did so in order to be compliant with the European Union’s GDPR privacy law which went into effect May 25, 2018. Users may now easily download a package of their personal user data. The data package I downloaded contained multiple JSON files along with subfolders for photos and videos, as shown in the visual below. Photos were in jpeg format, videos were MP4s – both easily accessible formats.
My data contained 265 photos and 3 videos. Due to time and resource constraints, I focused on my 50 most recent posts, excluding selfies and videos.
Data Preparation
The media.JSON file was the only JSON file I used for this project. The media file contains information on the content of the user’s posts, including fields for caption, location, and timestamp. I prepped the data as follows. The field giving date and time of the post came in as string. I converted it to a Date & Time field in Tableau as part of general cleanup, though I did not end up making use of that field for this project.
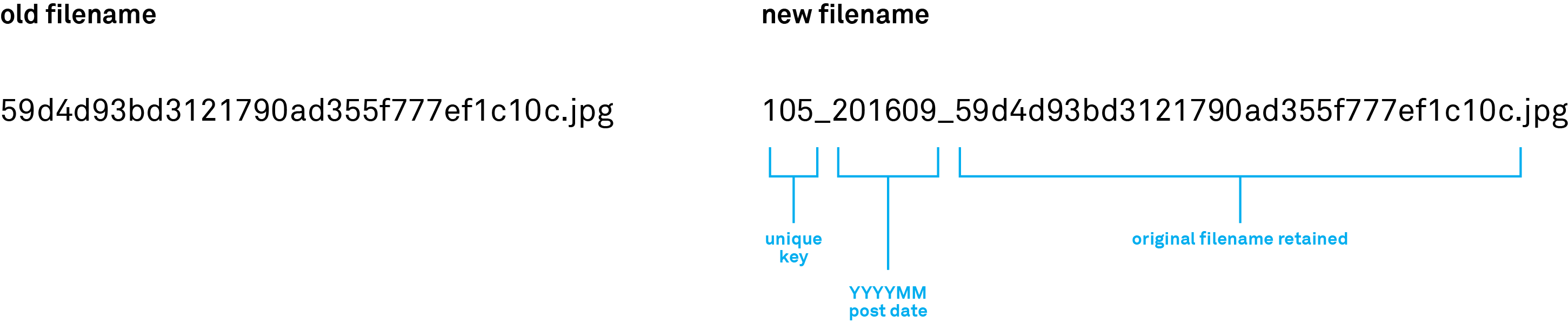
Image names for the photos were only provided as part of path, so I split the path to create an image name field. The image names were awkwardly long and unintelligible. I wanted image names that would be quicker to reference and which would provide information on when the image was posted. I determined my desired nomenclature, which would be to add a prefix to each image consisting of a unique serial index key (starting at the number 1 for the first image) and the year and month of the post in YYYYMM format. This yielded image filenames which were somewhat easier to identify from looking at just the first few characters, though they were still clunky, as I’d decided to retain the original image name in the filename in case it came in useful (it was not useful). The exhibit below shows my naming system. I created the new filenames as a Calculated Field in Tableau, then exported the old and desired filenames into a .CSV. I automated the filename changing process by batch renaming using the .CSV and commands in Terminal. Then I copied the 50 renamed images I was using as my dataset for this project into a separate folder.
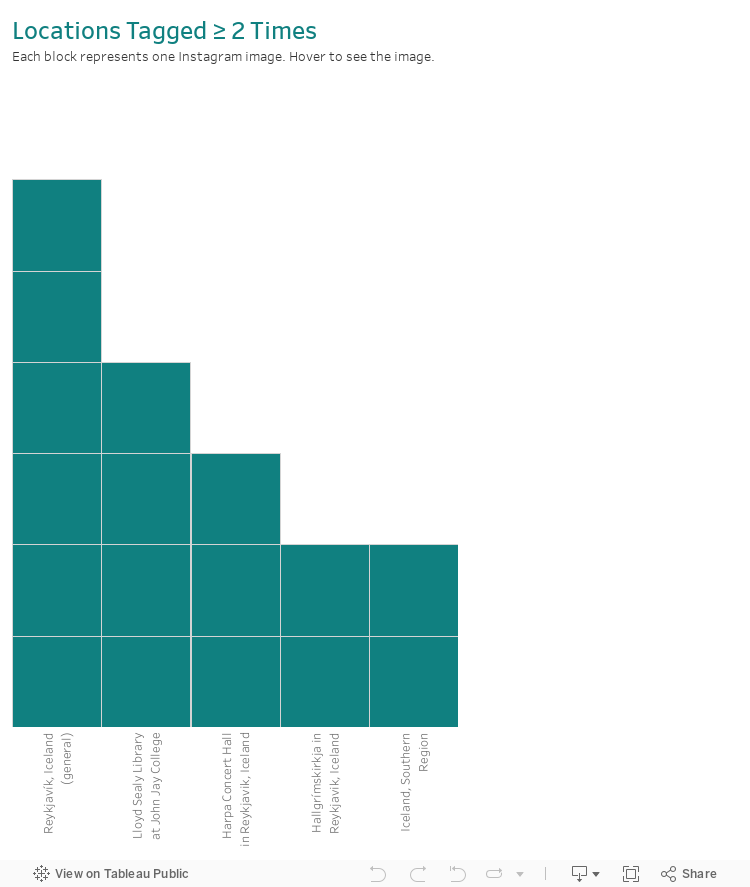
Visualization A: Top Locations Bar Chart with Images in Tooltip
Visualization A: Top Locations Bar Chart with Images in Tooltip I was able to accomplish my first aim by embedding images in the Tableau tooltips, as I have done in the segmented bar chart below. This chart shows locations or regions I tagged at least twice times in my 50 most recent posts. 14 records did not have location data, so they were excluded. Three of the four categories in the visualization below are in Iceland (I vacationed there in March), but I preferred to keep them separate rather than lumping them into one large “Iceland” category as that would have made the bar chart imbalanced and hard to read. The non-Icelandic location is the Lloyd Sealy Library at John Jay College of Criminal Justice, where I recently finished a bachelor’s degree.
Including images in the tooltips makes the visualization more engaging and provides a richer experience than descriptive words or metadata alone.
How to read this chart: hover over a section of the bar chart to see the corresponding image displayed. Please note, images may take a few seconds to load.
Setup for Artificial Intelligence (AI) Image Analysis
My second aim was to see how an AI would interpret the content of my image set and compare it to my own interpretation. There are multiple publicly accessible AIs available, some of which provide a certain number of searches for free. I chose to use Google Vision. Other image recognition AIs that would have also suited my purpose include Clarifai and Amazon’s Rekognition. I created a Google Cloud account and uploaded my image set into a “bucket”, which is Google Cloud’s storage and organizational construct. I had expected to process all 50 of my images as a batch, but that functionality required scripting to interface with the Google Cloud API. I explored doing so but was unsuccessful. Google does make an embedded API available on a webpage. I pointed this embedded API to each of my images, one at a time, to get the Google Vision AI to analyze the image content. I copy/pasted the top five label results for each image into a spreadsheet.
Separately, I created five labels of my own for each image and put those into the spreadsheet as well.
Visualization B: Word Clouds of AI Labels vs My Labels
Word clouds make it easy to pick out which labels were most often applied to my images by the Google Vision AI and which were most often applied by me. To reduce clutter, I chose to show only labels that were applied twice or more. We can quickly see that the word “architecture” is prominent in both clouds, signaling agreement between me and Google Vision that I post a proportionally large number of photos to Instagram that depict architecture. Other labels we both applied often are “water” and “sky”. The word clouds are also useful for identifying broad differences. I used proper location names as labels frequently, whereas Google Vision never did. My word cloud contains fewer items overall, indicating that I used a higher number of distinct labels, as a label must have been used at least twice to appear in the cloud.
How to read this chart: more commonly used words appear larger and darker. Hover over words to see how many times they were used as labels.

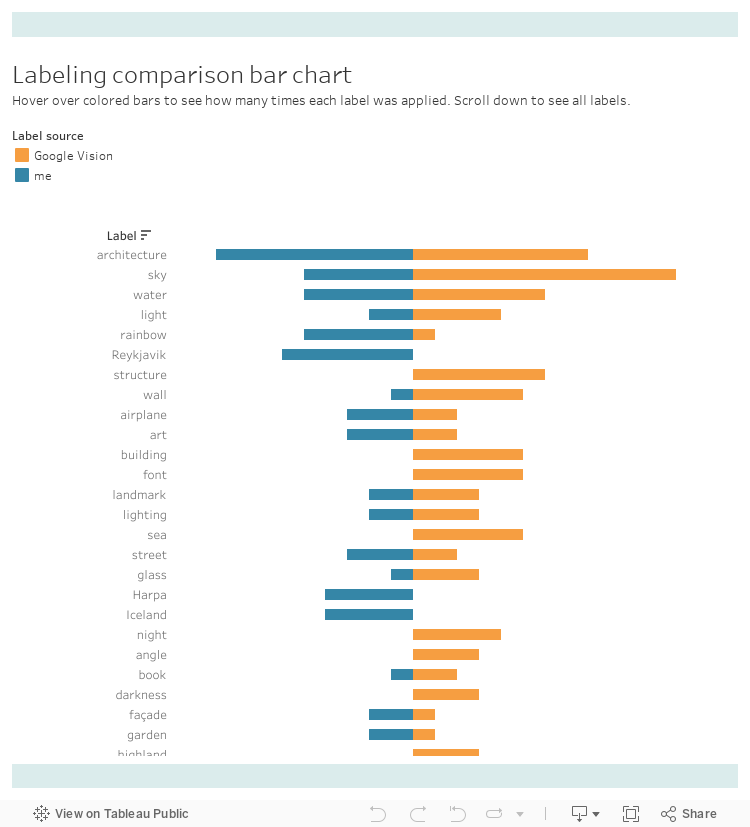
Visualization C: Bar Chart Comparing Label Use by Source
I had initially approached showing Google Vision and my label results together with a combined word cloud but it was not as easy to identify commonalities in the combined cloud as I hoped, even with the results coded by color (which I did eventually figure out). The length of each bar indicates how many times the label was used. Bars extend from a center axis, with my labels charted coming out from the left side of the axis and Google Vision’s labels charted coming out from the right side.
Sorting the labels alphabetically reveals Google Vision pulls disparate regional English spellings. It labeled one image with both “jewellry” and “jewelry making.” Other terms appear which are not commonly used in American English, such as “nunatak” and “loch”, while Google Vision also uses the very American slang “bling bling”.
How to read this chart: bar length corresponds with number of times the label was used. Labels can be sorted alphabetically by hovering over the column header and then clicking the dropdown that appears.
Visualization D: Single Image Details
There is a high degree of subjectivity in labeling, and my labels are not inherently correct. Still, it’s interesting to more closely examine exactly what the AI and I chose for each image. Below is a sampling of images with Vision’s top five labels and my own five labels shown alongside. In some instances our labeling was closely aligned. In others, Vision made clear errors or failed to identify the main subject matter. Vision did not always return at least five labels. In one instance shown below it did not venture any labels at all.
Reader note: the images below are not interactive content.







Conclusion and Next Steps
Using my own images allowed me to use my knowledge of the contents to assess Google Vision’s accuracy, particularly in the case of the naturally occurring basalt columns which Google Vision interpreted as a man-made wall in an ancient archeological site. Google Vision overall provided uneven results, with the focus of the picture being completely elided in some instances.
My immediate next step, which I have already started, is to learn Python. For this project it would have been useful to have a script that allowed all of my images to be processed by Google Vision as a batch. I expect that being able to write Python code will come in handy for many other projects as well.
Incorporating hashtag and/or caption data is an area that I would like to explore further. During my data prep phase I split out hashtags for each Instagram image from the captions. My intention was to include the hashtags in the location visualization tooltip. This was thwarted by not being able to include any other information in the tooltip when an image is in there. I would like to explore potential workarounds or other ways to include hashtag information in a visualizations that also displays the source image.
I would also in the future like to have a larger set of images analyzed by Google Vision and to figure out a grouping method for the resulting labels that reveals categorical advantages or disadvantages in either Google Visions or my own labeling execution.
Lastly, I think my static visualizations convey the information I’m trying to present well, but I would like to replace them with an interactive grid of thumbnails of the images. Clicking on a thumbnail would enlarge the image and also bring up the lists of Google Vision labels and my labels alongside each other for quick comparison.